
در آغاز 2017 بازوی آن دسته اول ماشین های اختصاصی (میلی لیتر) آموزش سخت افزار اعلام کرد. زیر نام پروژه Trillium شرکت پردازشگر ML اختصاصی برای محصولات مانند گوشی های هوشمند, همراه با تراشه دوم طراحی شده به طور خاص به سرعت تشخیص (NPD) شیء مورد استفاده پرده برداری کرد. بیایید به Trillium پروژه و طرح گسترده تر شرکت های بازار رو به رشد برای یادگیری سخت افزار دستگاه حفر عمیق تر.
مهم است که توجه داشته باشید که بازو را اعلام مربوط به سخت افزار کم قدرت استنباط است. آن پردازنده میلی لیتر و OD برای اجرای موثر آموزش دیده دستگاه وظایف در سطح مصرف کننده سخت افزار آموزش طراحی شده اند، به جای آموزش الگوریتم بر روی مجموعه داده های بزرگ مانند گوگل TPUs ابر به انجام طراحی شده اند. برای شروع، بازو در آنچه آن را می بیند به عنوان بزرگترین بازار دو میلی لیتر استنباط سخت افزار تمرکز — پروتکل/نظارت دوربین های گوشی های هوشمند و اینترنت.
ماشین یادگیری پردازنده جدید
با وجود دستگاه اختصاصی جدید آموزش سخت افزار اطلاعیه با پروژه Trillium، بازوی بقایای اختصاص داده شده به حمایت از این نوع وظایف در پردازنده و gpu ها آن بیش از حد، بهینه سازی با ضرب توابع داخل آن آخرین هسته پردازنده و پردازنده گرافیکی. Trillium این قابلیت با سخت افزار بهینه تر به شدت افزایش، قرعه کشی قادر می سازد وظایف یادگیری ماشین با کارایی بالاتر و قدرت کمتر انجام می شود. اما پردازنده ML بازو را فقط شتاب دهنده ندارد — این پردازنده در حق خود است.

پردازنده دارای توان عملیاتی اوج صدر 4.6 در پاکت قدرت 1.5 W آن را برای تلفن های هوشمند و محصولات قدرت حتی پایین تر مناسب. این تراشه راندمان قدرت 3 تاپ/W، براساس 7 اجرای نانومتر، قرعه کشی بزرگ برای توسعه محصول آگاهانه انرژی می دهد. برای مقایسه، دستگاه معمولی تلفن همراه فقط ممکن است قادر به ارائه سراسر TOPs 0.5 ریاضی کم عمق باشد.
جالب توجه است، پردازنده ML بازو را رویکردی متفاوت به برخی از تولید کنندگان تراشه گوشی های هوشمند که به پردازنده های سیگنال دیجیتال (DSPs) جهت اجرای وظایف یادگیری ماشین در پردازنده های خود را بالا پایان repurposed بکنه. در طول چت MWC معاونت بازوی همکار و جنرال موتورز ماشین یادگیری گروه جم دیویس، ذکر خرید شرکت DSP است گزینه ای را به این بازار سخت افزار، اما که در نهایت شرکت در زمین تا راه حل به طور خاص تصمیم بهینه سازی شده برای رایج ترین عملیات.
بازو را ML پردازنده دارای 4 و 6 x افزایش عملکرد بیش از گوشی های معمولی همراه با مصرف برق کاهش می یابد.
پردازشگر ML بازو را منحصرا برای عملیات 8 بیتی عدد صحیح و convolution شبکه های عصبی (CNN) طراحی شده است. این متخصص در افزایش توده های کوچک بایت اندازه داده است که باید به آن سریع تر و کارآمد تر نسبت به هدف کلی DSP که این نوع از وظایف. سی ان ان برای تشخیص تصویر احتمالا رایج ترین وظیفه میلی لیتر در حال حاضر به طور گسترده ای استفاده می شود. اگر شما نگرانم چرا 8 بیتی، بازوی داده 8 بیتی است نقطه شیرین برای دقت در مقابل عملکرد با سی ان ان و ابزار توسعه بالغ ترین هستند دیده می شود. اگر شما به آن نیاز نیست فراموش کردن که چارچوب اندیشه NN تنها پشتیبانی از INT8 و FP32، آخر که در حال حاضر در پردازنده و gpu ها اجرا می شود.
بزرگترین عملکرد و انرژی تنگنا، به خصوص در محصولات تلفن همراه حافظه پهنای باند و توده ضرب ماتریس نیاز به مقدار زیادی از خواندن و نوشتن است. برای رفع این مسئله، بازوی چانک حافظه داخلی برای سرعت بخشیدن به اعدام بود. اندازه این استخر حافظه متغیر است و انتظار دارد که بازو به ارائه مجموعه ای از طرح های بهینه سازی شده برای شرکای آن بسته به مورد استفاده. ما به نگاه 10s کیلوبایت حافظه برای اجرای هر یک از موتور دربندی رتبهٔ در حدود 1 مگابایت در طرح بزرگترین. این تراشه نیز فشرده سازی lossless در میلی لیتر وزن و فراداده ذخیره تا 3 x در پهنای باند استفاده می کند.
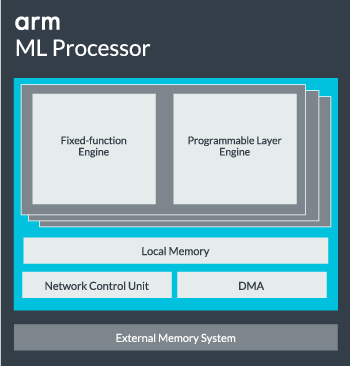
بازو را پردازنده طراحی شده برای ML عملیات 8 بیتی عدد صحیح و شبکه های عصبی convolution است.
هسته پردازنده میلی لیتر را می توان از تک هسته ای تا 16 موتور اعدام برای افزایش عملکرد پیکربندی شده است. هر کدام شامل بهینه سازی موتور تابع ثابت و همچنین لایه های قابل برنامه ریزی. موتور ثابت تابع معامله convolution محاسبه با واحد ضرب و جمع آوری (MAC) 128 گسترده در حالی که موتور برنامه ریزی لایه مشتق تکنولوژی میکروکنترلر Arm را دسته حافظه و بهینه سازی مسیر داده ها برای دستگاه الگوریتم یادگیری اجرا می شود. این واحد در معرض برنامه ها به طور مستقیم برای برنامه نویسی نیست، اما که کامپایلر مرحله بهینه سازی واحد مک جای پیکربندی شده است نام ممکن است کمی گمراه کننده است.
در نهایت، پردازنده شامل واحد دسترسی مستقیم حافظه (DMA) برای اطمینان از دسترسی سریع مستقیم به حافظه در قسمت های دیگر سیستم. پردازشگر ML می تواند تابع به عنوان مسدود کردن IP مستقل خود با رابط آس: به مطلب برای الحاق به SoC، یا فعالیت به عنوان بلوک ثابت خارج از SoC. به احتمال زیاد، ما ML هسته نشسته کردن حافظه اتصال داخل SoC درست مثل GPU یا پردازنده نمایش را دید. از اینجا، طراحان می تواند تراز کردن هسته ML با پردازنده در DynamIQ خوشه ای و به اشتراک گذاشتن دسترسی به حافظه کش از طریق snooping کش نزدیک است، اما بسیار قرار دادی است که راه حل است که احتمالا نمی بینم به طور کلی استفاده از حجم کار دستگاه های مانند تراشه های تلفن همراه.
اتصالات همه چیز را با هم
سال گذشته بازوی پرده برداری آن قشر A75 و A55 پردازنده و GPU G72 مالی بالا پایان، اما آن اختصاصی ماشین یادگیری سخت افزار تا تقریبا یک سال بعد پرده نیست. با این حال، بازوی یکسری تمرکز روی شتابان دستگاه مشترک یادگیری عملیات داخل آن سخت افزار آخرین محل بود و این همچنان بخشی از استراتژی شرکت رفتن به جلو.
آن آخرین مالی G52 پردازنده گرافیکی برای دستگاه های جریان اصلی باعث بهبود عملکرد وظایف یادگیری ماشین 3.6 بار لطف معرفی پشتیبانی ضرب داخلی (Int8) و چهار ضرب-عملیات در هر چرخه در هر خط تجمع. ضرب داخلی پشتیبانی نیز در A75 A55 و G72 ظاهر می شود.
بازوی بهینه سازی workloads میلی لیتر را در خود پردازنده و gpu ها بیش از حد ادامه خواهد داد.
حتی با OD و ML پردازنده های جدید، دست به حمایت از وظایف یادگیری ماشین شتاب در سراسر آن آخرین پردازنده و gpu ها ادامه دارد. آن ماشین آینده اختصاص داده شده به آموزش سخت افزار به این کارها را کارآمد تر مناسب وجود دارد، اما همه بخشی از مجموعه گسترده ای از راه حل های طراحی شده را به طیف گسترده ای از محصولات همکاران تهیه.
علاوه بر ارائه انعطاف پذیری “در سراسر عملکرد ها و انرژی های مختلف امتیاز به همکاران خود یک رویکرد این اهداف کلیدی بازو را ناهمگن مهم است حتی در آینده دستگاه مجهز به پردازشگر میلی لیتر به قدرت بهره وری بهینه سازی. به عنوان مثال، آن ارزش تأمین انرژی تا هسته میلی لیتر به سرعت انجام کار زمانی که پردازنده در حال اجرا، بنابراین بهتر است برای بهینه سازی workloads در پردازنده بیش از حد ممکن است. در تلفن, تراشه میلی لیتر به تنها به بازی برای دیگر در حال اجرا، بیشتر خواستار بارهای شبکه عصبی آمده است.

از تک برای پردازنده های چند هسته ای و gpu ها از طریق دو ليتر اختیاری پردازنده است که تمام راه را تا 16 هسته (موجود در داخل و خارج از خوشه هسته SoC)، میتواند در بازوی محصولات اعم از سخنرانان هوشمند ساده دو مستقل وسایل نقلیه و مراکز داده می تواند پشتیبانی، که نیاز به سخت افزار قوی تری. به طور طبیعی، این شرکت نیز تهیه نرم افزار به این مقیاس پذیری.
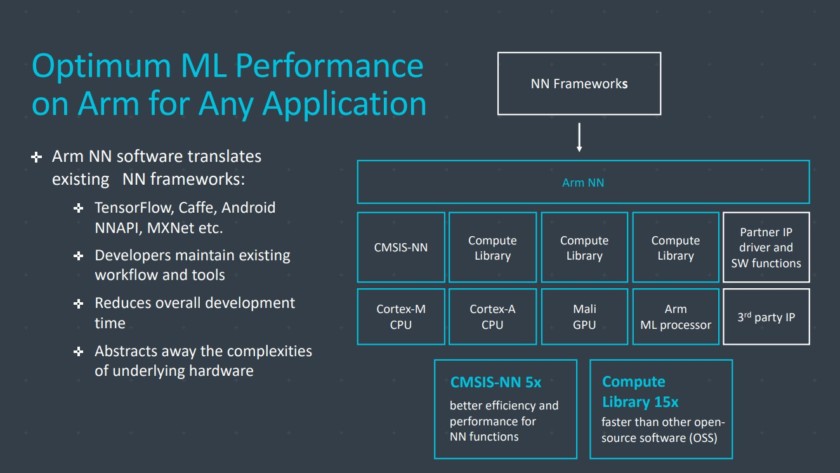
این شرکت در واقع کتابخانه ابزار برای عمل ماشین یادگیری کارها در سراسر شرکت پردازنده، پردازنده گرافیکی و در حال حاضر ML قطعات سخت افزاری هست. کتابخانه ارائه می دهد توابع سطح پایین نرم افزار برای پردازش تصویر، چشم انداز، تشخیص گفتار، و مانند، که اجرا در قابل استفاده ترین قطعه از سخت افزار. بازوی حتی برنامه های کاربردی تعبیه شده با آن دانه CMSIS NN برای ریزپردازنده قشر M پشتیبانی میکند. CMSIS NN حدود 5.4 برابر بیشتر توان عملیاتی و بالقوه 5.2 بار صرفه جویی در انرژی بیش از توابع پایه ارائه می دهد.
کار را بازوی در کتابخانه های کامپایلر و درایور تضمین می کند که توسعه دهندگان نرم افزار لازم نیست که به نگرانی در مورد محدوده تحت دروغ سخت افزار.
چنین امکانات گسترده ای از پیاده سازی سخت افزار و نرم افزار کتابخانه نرم افزار انعطاف پذیر نیاز بیش از حد, آن است که نرم افزار شبکه عصبی بازو را می آید. شرکت نمی باشد به جای محبوب چارچوب مانند TensorFlow یا Caffe دنبال اما ترجمه این چارچوب را به کتابخانه های مربوط به اجرای بر روی سخت افزار هر محصول خاص. اگر تلفن شما پردازنده Arm را نداشته باشند، بنابراین ML کتابخانه هنوز با اجرای وظیفه در CPU یا GPU کار می کنند. پنهان کردن پیکربندی پشت صحنه دو ساده توسعه هدف اینجا است.
دستگاه یادگیری امروز و فردا
در حال حاضر، بازوی مستقیما در تأمین انرژی پایان استنباط طیف یادگیری ماشین را اجازه می دهد مصرف کنندگان برای اجرای الگوریتم های پیچیده کارآمد در دستگاه های خود (اگر چه شرکت حکومت است متمرکز شده است امکان از درگیر شدن در سخت افزار ماشین یادگیری آموزش در برخی از نقطه در آینده). با سرعت بالا 5 g اینترنت هنوز سال دور و افزایش نگرانی های خود را در مورد حفظ حریم خصوصی و امنیت تصمیم بازو را به ML که محاسبات قدرت لبه به جای تمرکز در درجه اول به عنوان گوگل به نظر می رسد مانند حرکت صحیح در حال حاضر. تلفن های مرتبط با مقاله “/>
 برای SRAM و واحد سیستم بهینه سازی شده برای 16nm مقرون به صرفه و فرآیندهای برش لبه 7nm ارائه دهد. ما احتمال بازو را میلی لیتر اختصاص داده شده و پردازنده های تشخیص جسم در هر گوشی های هوشمند امسال نمی بینم. در عوض، ما به صبر کنید تا 2019 به گرفتن دست های ما در برخی از اولین گوشی های بهره گیری از پروژه Trillium و سخت افزار همراه خود داشته باشد.
برای SRAM و واحد سیستم بهینه سازی شده برای 16nm مقرون به صرفه و فرآیندهای برش لبه 7nm ارائه دهد. ما احتمال بازو را میلی لیتر اختصاص داده شده و پردازنده های تشخیص جسم در هر گوشی های هوشمند امسال نمی بینم. در عوض، ما به صبر کنید تا 2019 به گرفتن دست های ما در برخی از اولین گوشی های بهره گیری از پروژه Trillium و سخت افزار همراه خود داشته باشد.

برای SRAM و واحد سیستم بهینه سازی شده برای 16nm مقرون به صرفه و فرآیندهای برش لبه 7nm ارائه دهد. ما احتمال بازو را میلی لیتر اختصاص داده شده و پردازنده های تشخیص جسم در هر گوشی های هوشمند امسال نمی بینم. در عوض، ما به صبر کنید تا 2019 به گرفتن دست های ما در برخی از اولین گوشی های بهره گیری از پروژه Trillium و سخت افزار همراه خود داشته باشد.