
در پیگیری بیشتری گرافیک عملکرد مالی G76. تعدادی از این ترفند مهم در حال حاضر ساخته شده راه خود را به اواسط ردیف مالی G52 اما G76 هدف عملکرد فشار دو تا دیگر 50 درصد ها فقط تک.
برای دیدن چگونه بازو هل دادن تراشه های خود عملکرد کارت نزدیک داخل مالی G76 ببینیم.
بیشتر اجرای خطوط بیشتر عملکرد
که ما را در اعلام کلید برای بهبود عملکرد لمس در دو برابر کردن تعداد اعدام موتور داخل هر هسته مالی G76 نهفته است. در معماری G7X مالی هر هسته حاوی سه موتور اعدام به عنوان چند MP1 در طرح نامگذاری محصول نشان داده — MP2 دو هسته و شش اجرای کل موتور و MP4 چهار هسته موتور اعدام 12 است. در مالی G52، شرکای IP گزینه دو و یا سه موتور اعدام برای انعطاف کم اواسط محدوده عملکرد.
این موتور اعدام اعدام خطوط عمل عددی موضوعات برای ریاضی می باشد. این همه اجرا به موازات هسته با موضوعات بیشتر می تواند ریاضی بیشتر در هر زمان انجام. با این حال، افزایش تعداد خطوط پهنای باند بافت پشتیبانی و قدرت و سیلیکون مورد نیاز منطقه می شود.
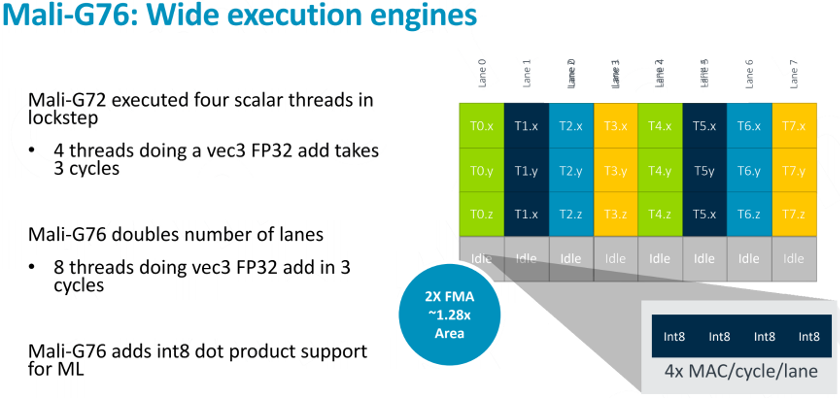
G76 مالی افزایش تعداد خطوط در هر واحد اعدام به هشت، تا از چهار با مالی G72 بازو. در مالی G76 تک هسته ای در حال حاضر 24 اجرای خطوط تا 12 در G72. این قابلیت محاسبه تک هسته ای، منجر به کوچک با 28 درصد افزایش در اندازه منطقه دو برابر. G76 هسته می خواهد کمی بزرگتر از قبلی G71 G72 هسته و اما آنها قوی تر است، بنابراین ما قطعا می توانید انتظار گرافیک اصلی تعداد دو در آینده گوشی های SoCs در مقایسه با نسل کنونی قرار می گیرند.
حداکثر تعداد هسته وقتی G76 مالی نیز با استفاده از کلاه هم اکنون که 20. اگر ما واقعا هرگز شاهد طرح های گوشی های هوشمند بیشتر از نوجوانان بالا به هر حال سرمایه گذاری که کاهش از حداکثر 32 هسته با G72 است. با وجود کاهش تعداد هسته بیشترین تعداد اعدام خطوط در تنظیمات بزرگترین افزایش می دهد. 20-هسته مالی G76 480 خطوط اعدام در مقابل خطوط فقط 384 در راه اندازی هسته های 32 G72 مالی را ارائه می دهد. بنابراین اوج عملکرد در بزرگترین پیکربندی را می توان تا 25 درصد افزایش یافته است.
دوم از مزایای عمده از افزایش تعداد خطوط در هر موتور اعدام کاهش نسبی در مصرف برق است — هر هسته قدرت کارآمد برای همان حجم کار از هسته نسل قبلی است. این است زیرا قرعه کشی قدرت پردازنده گرافیکی اجزای بیشتر زمانی که پوسته پوسته شدن تا تعداد اعدام خطوط ثابت می ماند.
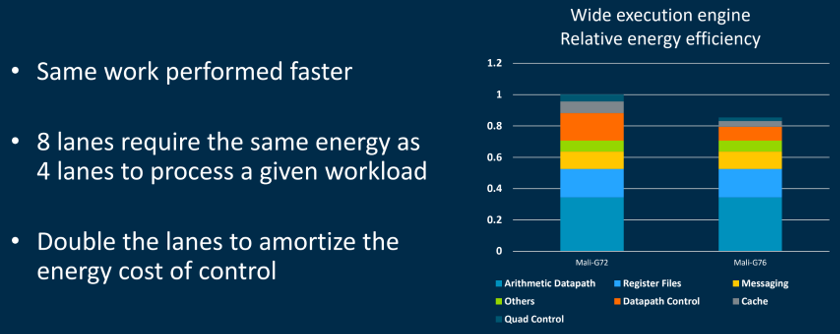
بازو را گرافیک بالا نشان می دهد که اگر چه هزینه انرژی نسبی حساب datapath و ثبت نام فایل ها همان باقی می ماند، پس انداز بهره وری بزرگ ساخته شده در کنترل مسیر داده ها وجود دارد، کش و کنترل چهار حزب آنتی ویروس. این اجازه می دهد تا G76 دو رخ کشیدن مقایسه با 30 درصد بهبود بهره وری انرژی G72 گره روند.
این خطوط اعدام در حال حاضر نیز INT8 ضرب ریاضی از طریق آموزش جدید پشتیبانی. پشتیبانی از خط هر چهار ضرب-عملیات در هر چرخه را تا حد زیادی بهبود توان عملیاتی تجمع می یابد. ما در حال حاضر این پیاده سازی در مالی متوسط G52 را دیده ام. بازو می گوید: این می تواند به بهبود بهره وری از ماشین یادگیری با استفاده از ضرب INT8 حدود 270 درصد نسبت به نسل قبلی.
طراحی
متعادل همراه با افزایش در محاسبه قدرت هر هسته، مالی G72 دارای تعدادی از پیشرفت های دیگر برای اطمینان از تغییر در طراحی هر گونه تنگناها ناخواسته را تولید نمی کند.
جدید پوشه های دوگانه بافت، که به عنوان نام نشان می دهد نمونه بافت معامله شده، تغییر اندازه و قرار دادن بر روی مدل های سه بعدی وجود دارد. قادر به texels دو در هر چرخه، دو برابر ظرفیت ارائه بیش از G72 است. مدیر چهار را اعدام هشت خط موتور بهینه شده و دو بافت نقشه نقاط آنتی ویروس خوبی با داده های تغذیه.
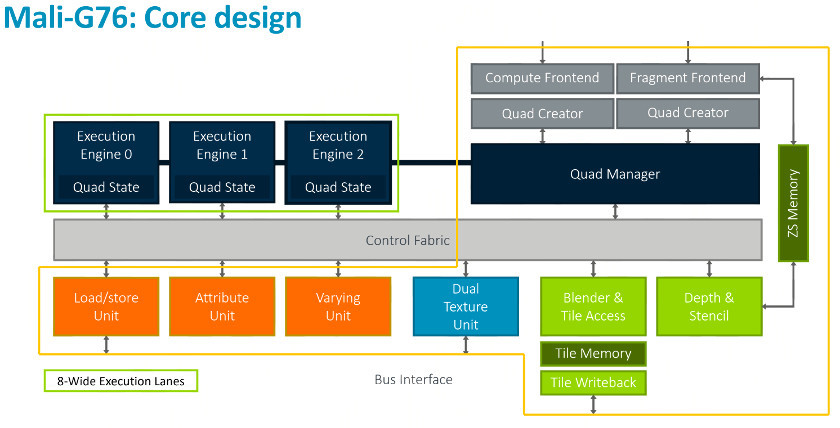
بازو را آخرین گرافیک حزب امکانات تعداد بهینه سازی کوچکتر دیگر، از جمله چند ضلعی از دستور لیست writeback برای جلوگیری از اصطبل در کش نتواند بارهای به بهبود بهره وری و عمق متفاوت قبل از بازوی بارهای پیش برای عملکرد بهتر چند رندر و TLS آدرس interleaving به منظور بهبود سرعت کش دلربا با سازماندهی فضای حافظه بهتر.
این نتایج در نه تنها تعداد بهینه سازی عملکرد اما نیز خطی عملکرد بیشتر پوسته پوسته شدن به عنوان هسته تعداد را افزایش می دهد. بازوی انتظار دارد که اساسا افزایش خطی دو عملکرد با هسته می شمارد به نوجوانان بالا و فقط از دست دادن حداقل زمانی که مهر و موم شده که در حال حاضر 20. قبلا وجود داشته است بیشتر قابل توجهی در عملکرد سود برچیند، وقتی تا نزدیک به تعداد حداکثر هسته پوسته پوسته شدن.
چه انتظار از gpu ها مالی G76
به ما می آیند انتظار از بازو را نسل گرافیک بهبود عملکرد و بهره وری انرژی برای بالا بردن قابل تنظیم هستند. پیاده سازی واقعی در گوشی های هوشمند می تواند با 50 درصد بهبود عملکرد گرافیکی را مشاهده کنید.
G76 مالی ارائه کمی مشکل نامگذاری هنگامی که اندازه گیری عملکرد هر چند. طرح های مالی G76 با کاهش تعداد هسته عملکرد قابل مقایسه و بهتر موجود G71 و G72 gpu ها با تعداد هسته های بالا فراهم خواهد کرد. G71 و G72 دیدم گوشی های با عملکرد بالا ارائه تعداد هسته در نوجوانان بالا اما بازوی انتظار دارد این سقوط به پایین نوجوانان با G76، حتی اگر عملکرد صعود خواهد کرد. به عنوان مثال، MP14 مالی G76 عملکرد بهتر از MP18 G72 مالی ارائه دهد.
هر هسته G76 مالی می تواند تا دو برابر در G72 قدرتمند.
درست مثل با قشر جدید-A76، G76 مالی جزء انعطاف پذیر طراحی شده در مقیاس تمام راه از اواسط ردیف عملکرد دستگاه های تلفن همراه تا لپ تاپ عملکرد بالاتر و همچنین محصولات علیرضا و VR بالقوه است.
مالی G76 معنی ما را ببینید دستگاه با استفاده از آن در بازار تا پایان سال برای شرکای بازو را به پروانه در حال حاضر، در دسترس است.




 برای SRAM و واحد سیستم بهینه سازی شده برای 16nm مقرون به صرفه و فرآیندهای برش لبه 7nm ارائه دهد. ما احتمال بازو را میلی لیتر اختصاص داده شده و پردازنده های تشخیص جسم در هر گوشی های هوشمند امسال نمی بینم. در عوض، ما به صبر کنید تا 2019 به گرفتن دست های ما در برخی از اولین گوشی های بهره گیری از پروژه Trillium و سخت افزار همراه خود داشته باشد.
برای SRAM و واحد سیستم بهینه سازی شده برای 16nm مقرون به صرفه و فرآیندهای برش لبه 7nm ارائه دهد. ما احتمال بازو را میلی لیتر اختصاص داده شده و پردازنده های تشخیص جسم در هر گوشی های هوشمند امسال نمی بینم. در عوض، ما به صبر کنید تا 2019 به گرفتن دست های ما در برخی از اولین گوشی های بهره گیری از پروژه Trillium و سخت افزار همراه خود داشته باشد.
